一个 map 长什么样
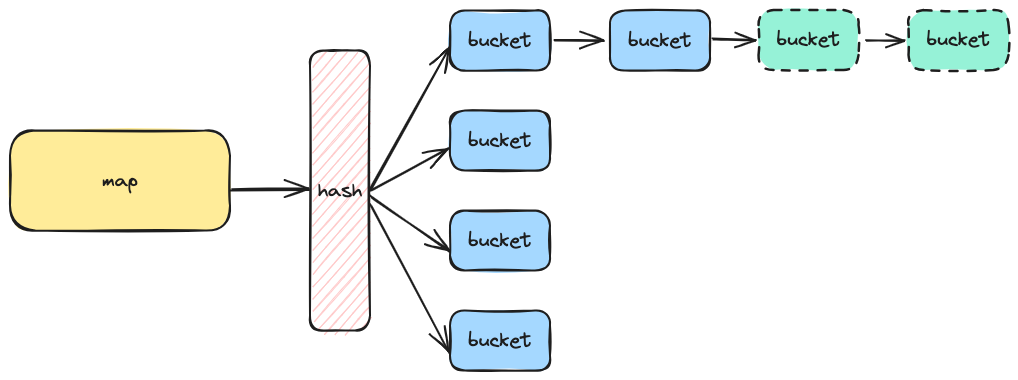 对于一个 map 来说,当我们操作一个元素,会通过对应的 hash 函数,散列到对应的存储桶数组 bucket,如果这个数组的空间不够,则会出现溢出,溢出的部分一般通过链表或者红黑树来存放。
对于一个 map 来说,当我们操作一个元素,会通过对应的 hash 函数,散列到对应的存储桶数组 bucket,如果这个数组的空间不够,则会出现溢出,溢出的部分一般通过链表或者红黑树来存放。
在 go 中对字典 map 的类型抽象定义如下,其中 Map 中的 Key 和 Value 分别用于确定 Map 的键值是哪种类型,而 Bucket 字段则指向哈希表的存储桶,存储真实数据:
// src/cmd/compile/internal/types/type.go
type Map struct {
Key *Type // 字典的 key 类型
Elem *Type // 字典的 value 类型
Bucket *Type // 指向哈希桶
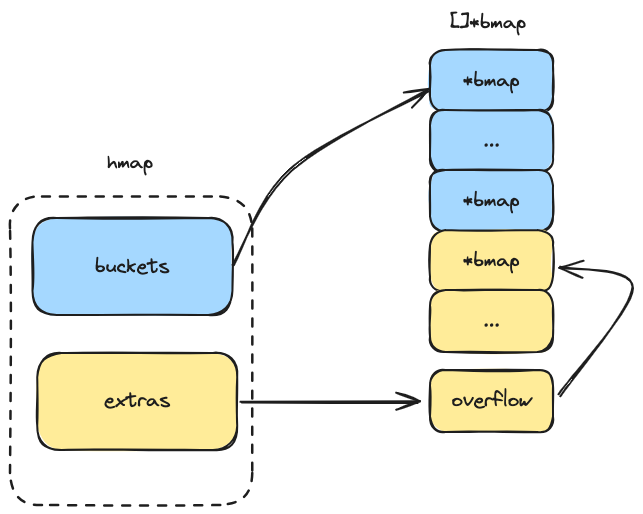
}创建 map 会返回一个 hmap 指针对象, hmap 中有若干个 buckets 存储桶,存储桶又由若干个 bmap 组成,hmap 和 bmap 的关系大致如下:
如何创建一个 map
我们都知道在 golang 中,创建一个 map 可以通过 make(map[string]int) 方式,但实际底层是如何创建的呢?让我们来一探究竟。
搜索源码,平时使用 new(map[string]int), make(map[string]), append, delete 等操作 map 的关键字,背后其实调用的是这些方法:
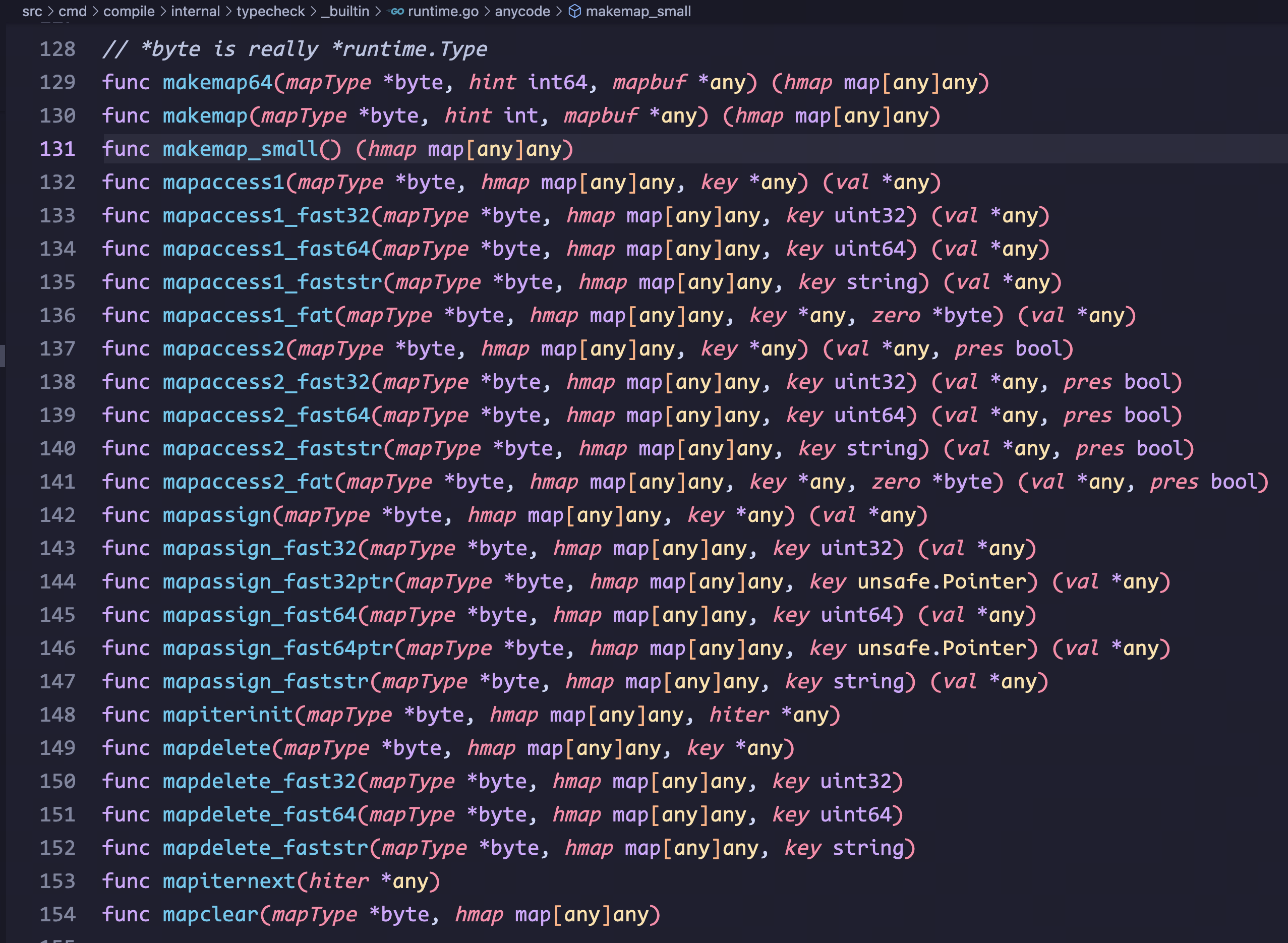
关于如何创建一个 map,我们可以留意这几个方法:
// src/cmd/compile/internal/typecheck/_builtin/runtime.go
// *byte is really *runtime.Type
func makemap64(mapType *byte, hint int64, mapbuf *any) (hmap map[any]any)
func makemap(mapType *byte, hint int, mapbuf *any) (hmap map[any]any)
func makemap_small() (hmap map[any]any)- makemap()
当编译期(runtime compile)能确定 map 或 map 的第一个存储桶 bucket 可以在栈上面进行创建,并且哈希表或存储桶不为空,会调用该方法进行创建:
# src/runtime/map.go
func makemap(t *maptype, hint int, h *hmap) *hmap {
// ...
}- makemakp_small()
当调用 make(map[k]v) 或 make(map[k]v, hint) 进行 map 实例化时,如果期望值 hint 的值是在编译期间(runtime compile)确定的值,判定 map 被分配在堆上,会调用 makemap_small() 方法进行创建 map:
// src/runtime/map.go
func makemap_small() *hmap {
h := new(hmap)
h.hash0 = uint32(rand()) // hash0 是 hmap 的哈希种子
return h
}- makemap64()
逻辑同上,在 64-bit 下调用该方法进行实例化;
需要注意的是,当期望值 hint 可以转为 int 类型时,使用
makemap来替代makemap64方式在 32-bit 的机型下能够可以更快、占用空间更小。
// src/runtime/map.go
func makemap64(t *maptype, hint int64, h *hmap) *hmap {
// 类型溢出情况
if int64(int(hint)) != hint {
hint = 0
}
return makemap(t, int(hint), h)
}深入了解 map 结构
hmap
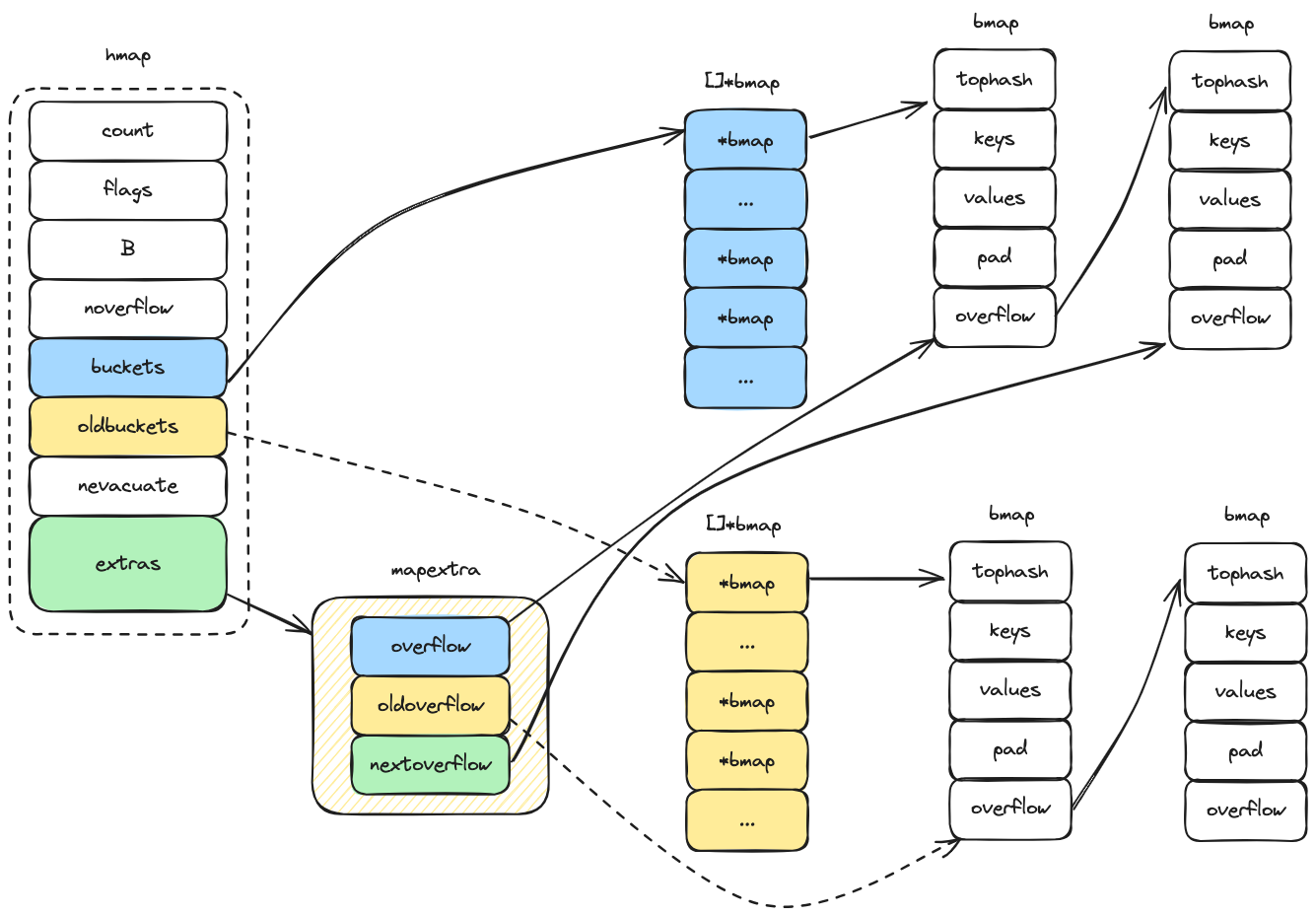
hmap 结构如下,其中的 extras 字段指向了一个溢出桶数组(具体来说,extras.overflow 字段指向 hmap.buckets,extra.oldoverflow 字段指向 hmap.oldbuckets):
// src/runtime/map.go
// A header for a Go map.
type hmap struct {
count int
flags uint8
B uint8 // 可以装下负载因子*2^B个元素(loadFactor * 2^B)
noverflow uint16 // 溢出桶的数量
hash0 uint32 // 哈希种子
buckets unsafe.Pointer // 指向 []*bmap 切片,桶的数量为 2^B 个,如果 count 为0的话,buckets 为 nil
oldbuckets unsafe.Pointer // map 扩容时使用,新扩的 buckets 的数量是当前的两倍
nevacuate uintptr // 在扩容过程中标记已经迁移了的索引,小于该索引值的元素已经从旧桶迁移到新桶
extra *mapextra // optional fields
}oldbuckets 会在哈希表扩容的过程中被使用,扩容时将原有的 buckets 赋值给 oldbuckets,buckets 再指向一个更大的数组;扩容时哈希表中的所有元素都需要从 oldbuckets 再搬迁回新的 buckets,就需要重新计算哈希值,这个过程被称为 rehashing1。为了避免迁移过程影响性能,整个过程采取的渐进式迁移。
mapextra
// src/runtime/map.go
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and elem do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and elem do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}mapextra 在 hmap 中是一个指针,指向包含溢出桶的结构;
overflow: 指向当前哈希表的溢出桶数组;哈希表在插入时可能会产生哈希冲突,冲突的元素就会存放在溢出桶中;oldoverflow: 指向旧哈希表的溢出桶数组;在哈希表扩容的过程中,因旧的存储桶需要迁移到新存储桶,此时oldoverflow指向的就是旧哈希表的溢出桶;nextoverflow: 指向下一个即将被使用的溢出桶;当插入新元素产生哈希冲突时,就会存放在nextoverflow所指向的桶;
bmap
bmap 中的 tophash 用于优化 map 的快速查找,每个 bmap 可以存储多个键值对,为了快速判断某个键是否在存储桶中,每个键都有对应的 tophash 值,当 tophash 值匹配后,才会进行完整的键值比较:
// src/runtime/map.go
type bmap struct {
// 在每个存储桶中,tophash 用于包含每个键的哈希值的最高字节,用于快速比较键值是否存在桶中;
// 当哈希表在进行迁移重哈希时,部分桶中的数据需要迁移到其他桶,minTopHash 就是一个阈值,
// 当 tophash[0] < minTopHash(值为5) 时,表示当前桶的元素处于迁移状态;
// 实际等于 tophash [8]uint8;
tophash [abi.MapBucketCount]uint8
// 下面紧跟的部分是存储桶的键值对,我们会在下面讲到;
// 需要注意,把所有的键和所有的值分别打包,会比键/值/键/值(key/elem/key/elem/...)这种形式更复杂一些;
// 但是这样设计可以避免在某些场景下需要进行内存填充(padding),比如 map[int64]int8,在进行交替存储的时候,
// 需要进行一定的填充才能保证内存对齐,使得能够更高效地访问;
// 紧跟着键值对的后面是指向溢出桶的 overflow 指针;
}tophash 字段的 abi.MapBucketCount 值在 src/internal/abi/map.go 中进行定义,MapBucketCount 为 8(1<<MapBucketCountBits) ,因此一个存储桶的长度为 8。
// src/internal/abi/map.go
const (
// Maximum number of key/elem pairs a bucket can hold.
MapBucketCountBits = 3 // log2 of number of elements in a bucket.
MapBucketCount = 1 << MapBucketCountBits
)我们上面分析了 bmap 存储桶的实际结构,很明显仅有一个 tophash 字段没有任何实际作用。因为在编译期间,还会动态增加一些字段,结构如下所示:
type bmap struct {
topbits [8]uint8 // 桶元素的哈希值
keys [8]keytype // 所有键
values [8]valuetype // 所有值
pad uintptr // 内存填充(非必须)
overflow uintptr // 指向溢出桶
}深入了解 map 创建过程
上面提到了,创建 map 时会调用 makemap 函数,函数具体实现如下:
// src/runtime/map.go
func makemap(t *maptype, hint int, h *hmap) *hmap {
// 通过 math.MulUintptr 计算初始散列表需要预留的内存空间的大小(期望数量 hint * 桶的大小 Bucket.Size_);
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// 如果结果溢出了(overflow = Bucket.Size_ > MaxUintptr/uintptr(hint)),
// 其中 MaxUintptr = ^uintptr(0) 即 (2^64-1,18446744073709551615);
// 或者大于最大可分配的大小,则重置 hint 期望值为 0,不分配内存空间。
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = uint32(rand())
// 获取一个合适的桶大小 B,桶数组可以在不超过负载因子的情况下容纳所有元素,而负载因子决定了桶的密度。
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// 如果 B 为 0,那么存储桶会延迟分配(在 mapassign 的时候);
// 如果 B 不为 0,就需要预分配桶的存储空间;
// 调用 makeBucketArray 来创建桶数组([]*bmap);
// 当桶的期望值很大的时候,需要比较长的时间来分配内存空间;
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// 如果需要额外的溢出桶,也同时分配对应的溢出桶空间;
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}哈希表的负载因子
选择一个合适的负载因子 loadFactor 很重要:
- 太大会导致过多的溢出桶;
- 太小会浪费很多的存储空间;
负载因子的一般计算方式如下:
- n 是使用数量
- m 是桶的总数量
在源码中负载因子的具体实现:
// src/runtime/map.go
// overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor.
func overLoadFactor(count int, B uint8) bool {
// 上面提到了 MapBucketCount(1<<MapBucketCountBits)等于8,
// loadFactorDen等于2,loadFactorNum(loadFactorDen * abi.MapBucketCount * 13 / 16)等于13(2*8*13/16),
// 而13主要是为了保证存储桶空间保持在80%(13/16)。
return count > abi.MapBucketCount && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}在不同的负载因子下的表现情况如下(64bit,map 的 key 和 value 都是 8 字节):
| 指标 | 描述 |
|---|---|
| loadFactor | 负载因子 |
| overflow | 溢出桶的占比 |
| bytes/entry | 每个键值对(key/elem pair)额外的存储空间浪费 |
| hitprobe | 访问一个存在的 key 所需要的查找次数 |
| missprobe | 访问一个不存在的 key 所需要的查找次数 |
| loadFactor | %overflow | bytes/entry | hitprobe | missprobe |
|---|---|---|---|---|
| 4.00 | 2.13 | 20.77 | 3.00 | 4.00 |
| 4.50 | 4.05 | 17.30 | 3.25 | 4.50 |
| 5.00 | 6.85 | 14.77 | 3.50 | 5.00 |
| 5.50 | 10.55 | 12.94 | 3.75 | 5.50 |
| 6.00 | 15.27 | 11.67 | 4.00 | 6.00 |
| 6.50 | 20.90 | 10.79 | 4.25 | 6.50 |
| 7.00 | 27.14 | 10.15 | 4.50 | 7.00 |
| 7.50 | 34.03 | 9.73 | 4.75 | 7.50 |
| 8.00 | 41.10 | 9.40 | 5.00 | 8.00 |
哈希表的桶是如何创建的
// 初始化存储桶;桶的最小数量为 2^b 次方个;
// 当 dirtyalloc 为 nil 时,会创建一个新的存储桶数组;
// 否则会复用先前的 dirtyalloc,清空内存空间并复用数组;
// h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b)
nbuckets := base
// For small b, overflow buckets are unlikely.
// Avoid the overhead of the calculation.
if b >= 4 {
// Add on the estimated number of overflow buckets
// required to insert the median number of elements
// used with this value of b.
nbuckets += bucketShift(b - 4)
sz := t.Bucket.Size_ * nbuckets
up := roundupsize(sz, !t.Bucket.Pointers())
if up != sz {
nbuckets = up / t.Bucket.Size_
}
}
if dirtyalloc == nil {
buckets = newarray(t.Bucket, int(nbuckets))
} else {
// dirtyalloc was previously generated by
// the above newarray(t.Bucket, int(nbuckets))
// but may not be empty.
buckets = dirtyalloc
size := t.Bucket.Size_ * nbuckets
if t.Bucket.Pointers() {
memclrHasPointers(buckets, size)
} else {
memclrNoHeapPointers(buckets, size)
}
}
if base != nbuckets {
// 为了更高效管理这些溢出桶,会预先提前创建好一些溢出桶;
// 同时为了尽可能低成本追踪这些溢出桶,会约定当溢出桶是空指针时,会增加一个 bumping 指针,以获得下一个可用的溢出桶;
// 而这个增加的安全非空指针,就是用的哈希表的 `buckets` 溢出桶数组来作为溢出桶的溢出指针;
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))
last.setoverflow(t, (*bmap)(buckets))
}
return buckets, nextOverflow
}在下一篇,我们会介绍下 map 为什么不是并发安全的,以及如何才能保证并发读写是安全的。
参考链接: